
Pas le temps ? Faites-le analyser par l'IA
Scraping : Le Web scraping (parfois appelé Harvesting) est une technique d’extraction du contenu de sites Web, via un script ou un programme, dans le but de le transformer pour permettre son utilisation dans un autre contexte. _Wikipedia
Scraping de sites WordPress
Alors que je faisais ma veille WordPress sur WPFormation, en parcourant les SERPs de Bing – Oui, il s’agit bien du moteur de recherches Bing mais on fait sa veille correctement ou pas ;) d’ailleurs je vous conseille à tous d’aller vous inscrire sur Bing Webmaster un très bon outil avec de nombreuses possibilités – J’ai découvert ceci :
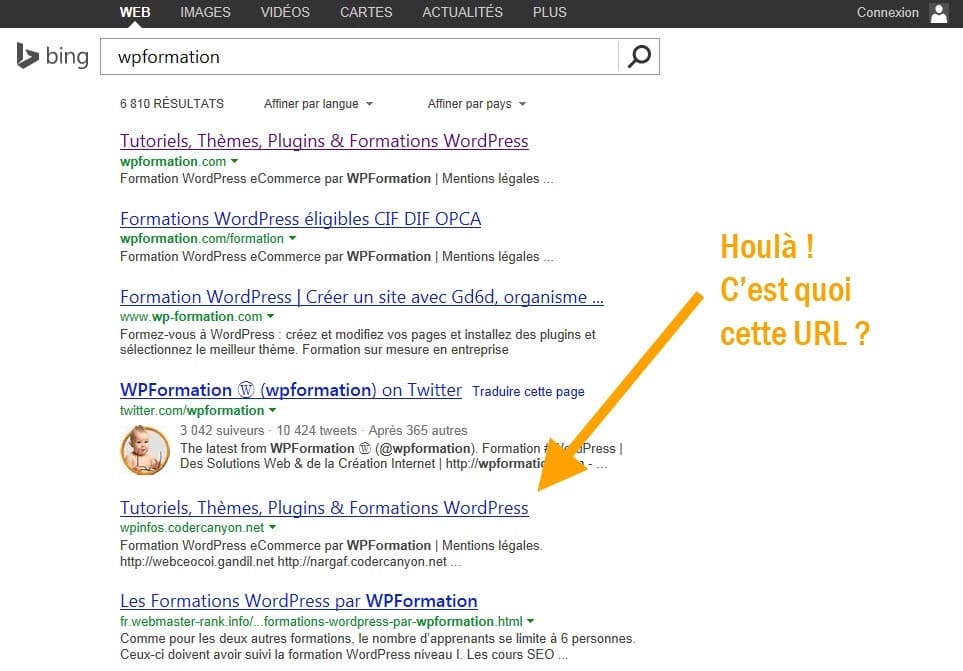
Sur le nom de mon site apparaît très clairement en position 5, une URL sortie de je ne sais où! Petit clic et voici une copie exacte de mon site! Plus fort encore, les liens internes sont fonctionnels, ainsi lorsque je clique sur un menu du site copieur, je reste sur la copie.
Au moment ou j’écris cet article, j’ai bien évidement corrigé le problème aussi l’exemple que je vous montre ci-dessous est celui du scrap de SeoMix également touché:
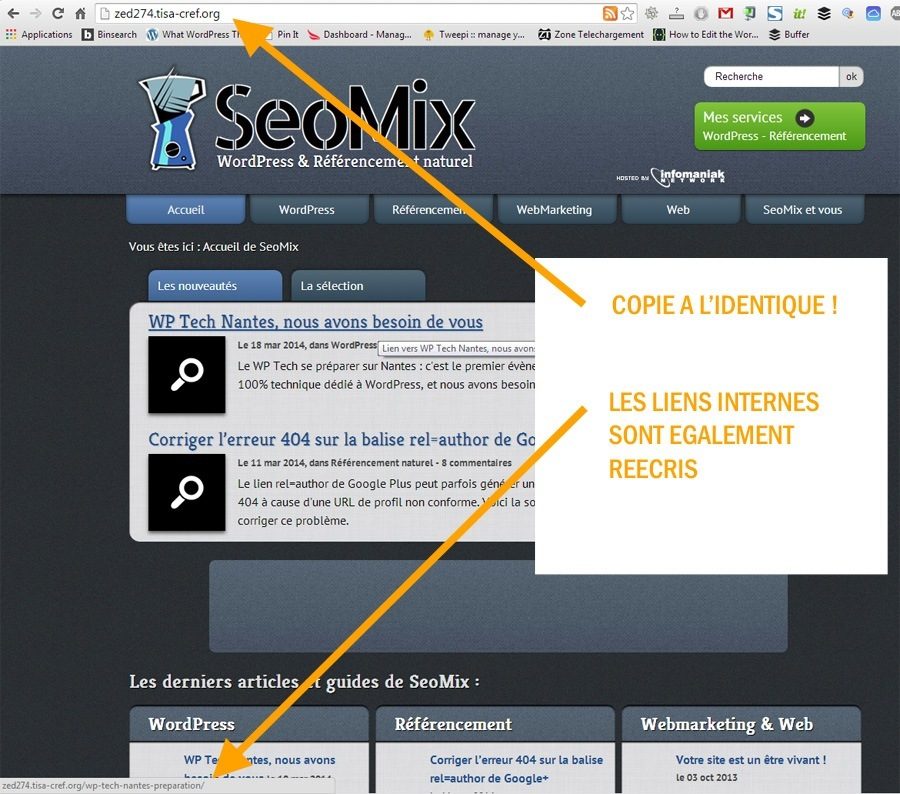
En discutant avec Benoit, je vais découvrir ainsi pas moins de 300 sites scrapés, sur plusieurs domaines différents. Certains sites WordPress sont entièrement copiés, d’autres partiellement:
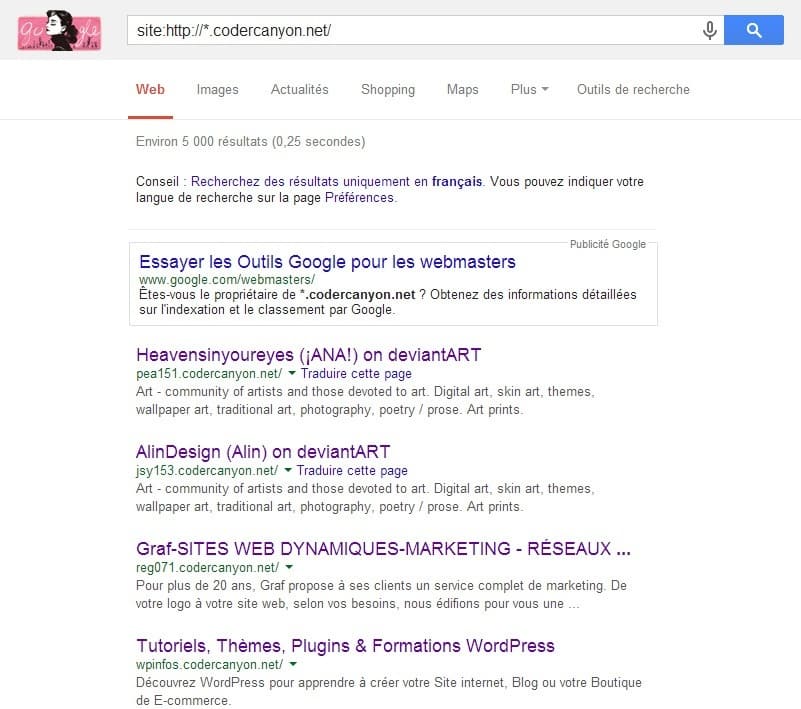
Attention : Les scrapers utilisent de nombreux domaines en passant par CloudFlare, il n’y a pas que codercanyon.net, on trouve également tisa-cref.org, tjoos.co, etc… par exemple le site de Daniel est scrapé sur pas moins de 2 domaines différents:(
Scraper mais dans quel but ?
C’est la première des questions, quel est donc l’intérêt de copier l’intégralité d’un site? C’est François du site Mitambo qui m’a éclairé: C’est du NSEO c’est à dire du Negative SEO.
François a détecté une pyramide à plusieurs niveaux donnant ainsi du poids à certains des sites copiés, l’objectif étant clairement de prendre des positions dans les SERPs et de détourner une partie du trafic.
Certains diront que ces techniques ne fonctionnent que sur des sites avec peu d'ancienneté et une autorité minimale, C’est faux! Je les renvoie à la 1ère capture d’écran de cet article (le scrap a eu lieu le 1er mai 2014) et sur Bing le site copieur apparaît déjà en position 5 dans les SERPs. Combien de temps lui aurait-il fallu pour progresser sur celles de Google?
Paul Sanches a créé une polémique sur le sujet qui a fait bouger Matt Cutts himself en faisant disparaître sa homepage de Google.fr (pas celle du blog mais le root). Donc le soucis de "pénalité" est bien réel.
Pour lutter efficacement contre ce type de NSEO, il faut placer des balises canonical dans les contenus qui affichent l’URL officielle (SEO by Yoast le fait). Ainsi si la page est scrapée et que le scraper n’a pas fait attention, au moins la canonical renvoie vers la bonne URL… mais dans mon cas présent, le scraper l’avait aussi changé…
Que faire en cas de Scrap ?
La première des choses à faire c’est d'identifier le problème, le site copieur est hébergé sur le CDN cloudflare, il devrait donc y avoir moyen de discuter avec eux… Et bien non, CloudFlare me répondra : "Nous sommes un fournisseur de réseau offrant un reverse proxy. Nous ne sommes pas un fournisseur d’hébergement. CloudFlare ne contrôle pas le contenu de ses clients"… Sic!
L’autre solution c’est de prévenir Google, il existe un formulaire, le Google Scraper Report. Cela vient d’un tweet de Matt Cutts donc on peut croire le formulaire légitime: Google-scraper-tool-185532.
Formulaire posté mais l’entête du formulaire précise ceci: "pour déclarer un contenu scrapé se positionnant mieux dans les SERPs que le contenu original". Il faut donc attendre de se faire passer devant pour réagir.
3ème solution, au vu des sites scrapés (Envato notamment), un petit tweet pour les prévenir, il auront forcément plus de poids et l’union ne fait-elle pas la force.
4ème solution, trouver l’astuce technique. En effet, comment mon site entier peut-il être copié? Comment se fait-il que lorsque je fais une modification elle se répercute immédiatement sur le site copieur?
@BoiteAWeb Julio nos sites web ont été scrapés voir http://t.co/Qau4mwTjBw et http://t.co/jpTVa9nPlA ainsi que + de 100 autres… #DMCA
— WP Formation Ⓦ 🇫🇷 (@wpformation) May 3, 2014
Solutions contre le Scrap
La solution viendra par Michael de IP_Solution qui a trouvé le serveur Nginx et de fait le proxy effectif vers wpformation, ainsi le moyen de les stopper en bloquant leurs IPs depuis le firewall de mon serveur.
Grégoire, dont le site a aussi été scrapé, a utilisé le plugin WordPress WordFence pour bloquer les IPs du serveur copieur.
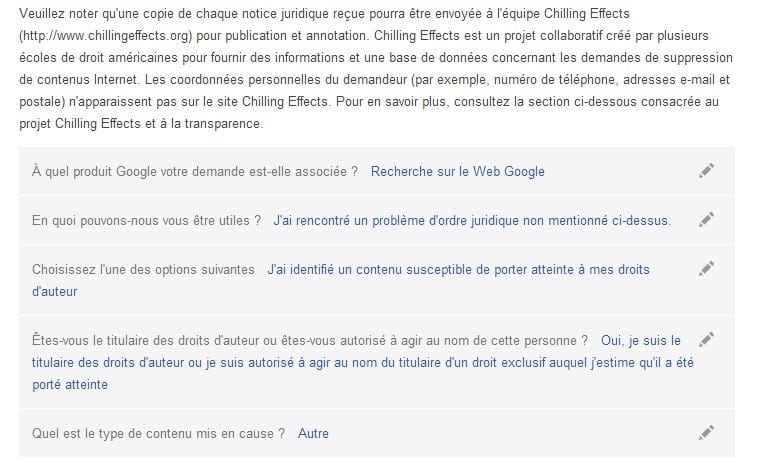
Signaler le contenu illicite depuis la page Suppression de contenu de Google, attention de bien remplir le formulaire (voir capture d’écran ci-après). Si le cas est avéré et pris en compte, Google supprimera le contenu de ses SERPs (Merci @Lumière de lune ;)
Sachez enfin qu’il existe aussi le service DMCA qui permet de déposer des plaintes mais cela ne concerne que la législation US mais ils disent bosser pour toute personne même hors des USA. Si eux agissent, c’est minimum 199$ sinon pour 10$ on peut créer sa plainte et ils vous expliquent la procédure à suivre.
Pour conclure ce billet, je vous rappellerais de ne pas oublier de surveiller votre contenu, de faire votre veille technique et de suivre vos positions. Utilisez des outils tels que Copyscape et/ou DMCA pour vérifier que vos contenus ne soient pas copiés, et surtout… restez vigilant;)
Chaque mois, je passe 15 heures en veille WordPress. Vous, vous recevez un email de 3 minutes.
Sécurité, performance, SEO, nouveautés, IA : l'essentiel trié, vérifié et expliqué par un formateur WordPress depuis 2012 et fondateur de WPServeur.
Double opt-in : un email de confirmation à valider. Max 2 emails/mois. Données jamais revendues ni échangées. Désabonnement en 1 clic.
